
CobiGen
Configuration
CobiGen is maintaining a home directory further referenced in this documentation as $cghome, which is used to maintain temporary or transient data. The home folder is determined with the following location fall-back:
-
System environment variable
COBIGEN_HOME(e.g.C:\project\ide\conf\cobigen-home) -
.cobigendirectory in OS user home (e.g.~/.cobigen)
The actual configuration of CobiGen is maintained by a single folder or jar. The location can be configured with respect to the implemented configuration fall-back mechanism. CobiGen will search for the location of the configuration in the following order:
-
A configuration jar or directory, which is passed to CobiGen by the Maven or Eclipse integration or any other program using the CobiGen programming interface: 1.1. the Maven integration allows to configure a jar dependency to be included in the currently running classpath (of interest for maven configuration 1.2. the Eclipse integration allows to specify a
CobiGen_Templatesproject in the eclipse workspace -
The file
$cghome/.cobigenexists and the propertytemplatesis set to a valid configuration (e.g.templates=C:\project\ide\conf\templatesortemplates=C:\project\ide\conf\templates.jar) Hint: Check for log entry likeValue of property templates in $cghome/.cobigen is invalidto identify an invalid configuration which is not taken up as expected -
The folder
$cghome/templates/CobiGen_Templatesexists -
The lexicographical sorted first configuration jar of the following path pattern
$cghome/templates/templates-([^-]+)-(\\d+\\.?)+.jarif exists (e.g.templates-devon4j-2020.04.001) -
CobiGen will automatically download the latest jar configuration from maven central with
groupIdcom.devonfw.cobigenandartifactIdtemplates-devon4jand take it like described in 4.
Within the configuration jar or directory you will find the following structure:
CobiGen_Templates
|- templateFolder1
|- src
|- main
|- templates
|- template1
|- templates
|- templates.xml
|- templateFolder2
|- context.xmlSince: CobiGen 2021.12.007:
template-sets
|- downloaded
|- template-set1.jar
|- template-set2.jar
|- template-set-utilities.jar
|- adapted
|- template-set1
|- src
|- main
|- templates
|- templates
|- context.xml
|- templates.xml
|- template-set2Find some examples here.
CobiGen Configuration File
The CobiGen configuration file located at: $home/.cobigen can be used to set the path to the custom templates as well as the template sets project.
You can also specify attributes to control the behaviour of your template sets.
Templates
For a custom templates folder simply set the templates parameter like this:
templates=C:\\project\\ide\\conf\\templatesFor a custom templates jar simply set the templates parameter like this:
templates=C:\\project\\ide\\conf\\templates\\my-custom-templates-devon4j-2021.06.001.jarTemplate Sets
Since: CobiGen 2021.12.006
For a custom template-sets folder simply set the template-sets parameter like this:
template-sets=C:\\project\\ide\\conf\\template-setsTemplate set attributes
Since: CobiGen 2021.12.006
You can specify template-sets attributes f.e. to restrict the teams to ask for default templates provided by CobiGen. There are four custom template-sets attributes:
-
template-sets.groupIds: Search for template-set artifacts by that configuration key configure multiple (comma separated)groupIds. By default, (public) CobiGengroupIdwill be used. -
template-sets.allow-snapshots: Allow snapshots of template-sets to be offered for template-set development purposes. By default, no snapshots should be queried. -
template-sets.disable-default-lookup: Disable by default querying of default publicgroupIdsconfigured in CobiGen. -
template-sets.hide:Hide very specific template sets or versions of template sets. -
template-sets.installed:Template sets will be available at CobiGen startup if template sets are not already adapted.
The key template-sets.hide and template-sets.installed accept maven coordinate with the following format: groupID:artifactID:version the version is optional and if omitted the LATEST version will be used. You can specify multiple maven coordinates separated with ,.
-
An example of how such a configuration should look like:
template-sets.groupIds=com.devonfw.cobigen.templates,jaxen,jakarta.xml.bind
template-sets.allow-snapshots=true
template-sets.disable-default-lookup=false
template-sets.hide=com.devonfw.cobigen.templates:crud-angular-client-app:2021.12.007-SNAPSHOT
template-sets.installed=com.devonfw.cobigen.templates:crud-angular-client-app:2021.12.007-SNAPSHOT, com.devonfw.cobigen.templates:crud-java-server-app:Context Configuration
The context configuration (context.xml) always has the following root structure:
<?xml version="1.0" encoding="UTF-8"?>
<contextConfiguration xmlns="http://capgemini.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="1.0">
<triggers>
...
</triggers>
</contextConfiguration>The context configuration has a version attribute, which should match the XSD version the context configuration is an instance of. It should not state the version of the currently released version of CobiGen. This attribute should be maintained by the context configuration developers. If configured correctly, it will provide a better feedback for the user and thus higher user experience. Currently there is only the version v1.0. For further version there will be a changelog later on.
Trigger Node
As children of the <triggers> node you can define different triggers. By defining a <trigger> you declare a mapping between special inputs and a templateFolder, which contains all templates, which are worth to be generated with the given input.
<trigger id="..." type="..." templateFolder="..." inputCharset="UTF-8" >
...
</trigger>-
The attribute
idshould be unique within an context configuration. It is necessary for efficient internal processing. -
The attribute
typedeclares a specific trigger interpreter, which might be provided by additional plug-ins. A trigger interpreter has to provide an input reader, which reads specific inputs and creates a template object model out of it to be processed by the FreeMarker template engine later on. Have a look at the plug-in’s documentation of your interest and see, which trigger types and thus inputs are currently supported. -
The attribute
templateFolderdeclares the relative path to the template folder, which will be used if the trigger gets activated. -
The attribute
inputCharset(optional) determines the charset to be used for reading any input file.
Matcher Node
A trigger will be activated if its matchers hold the following formula:
!(NOT || … || NOT) && AND && … && AND && (OR || … || OR)
Whereas NOT/AND/OR describes the accumulationType of a matcher (see below) and e.g. NOT means 'a matcher with accumulationType NOT matches a given input'. Thus additionally to an input reader, a trigger interpreter has to define at least one set of matchers, which are satisfiable, to be fully functional. A <matcher> node declares a specific characteristics a valid input should have.
<matcher type="..." value="..." accumulationType="...">
...
</matcher>-
The attribute
typedeclares a specific type of matcher, which has to be provided by the surrounding trigger interpreter. Have a look at the plug-in’s documentation, which also provides the used trigger type for more information about valid matcher and their functionalities. -
The attribute
valuemight contain any information necessary for processing the matcher’s functionality. Have a look at the relevant plug-in’s documentation for more detail. -
The attribute
accumulationType(optional) specifies how the matcher will influence the trigger activation. Valid values are:-
OR (default): if any matcher of accumulation type OR matches, the trigger will be activated as long as there are no further matchers with different accumulation types
-
AND: if any matcher with AND accumulation type does not match, the trigger will not be activated
-
NOT: if any matcher with NOT accumulation type matches, the trigger will not be activated
-
Variable Assignment Node
Finally, a <matcher> node can have multiple <variableAssignment> nodes as children. Variable assignments allow to parametrize the generation by additional values, which will be added to the object model for template processing. The variables declared using variable assignments, will be made accessible in the templates.xml as well in the object model for template processing via the namespace variables.*.
<?xml version="1.0" encoding="UTF-8"?>
<contextConfiguration xmlns="http://capgemini.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="1.0">
<triggers>
<trigger id="..." type="..." templateFolder="...">
<matcher type="..." value="...">
<variableAssignment type="..." key="..." value="..." />
</matcher>
</trigger>
</triggers>
</contextConfiguration>-
The attribute
typedeclares the type of variable assignment to be processed by the trigger interpreter providing plug-in. This attribute enables variable assignments with different dynamic value resolutions. -
The attribute
keydeclares the namespace under which the resolved value will be accessible later on. -
The attribute
valuemight declare a constant value to be assigned or any hint for value resolution done by the trigger interpreter providing plug-in. For instance, iftypeisregex, then onvalueyou will assign the matched group number by the regex (1, 2, 3…)
Container Matcher Node
The <containerMatcher> node is an additional matcher for matching containers of multiple input objects.
Such a container might be a package, which encloses multiple types or---more generic---a model, which encloses multiple elements. A container matcher can be declared side by side with other matchers:
ContainerMatcher Declaration<?xml version="1.0" encoding="UTF-8"?>
<contextConfiguration xmlns="http://capgemini.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="1.0">
<triggers>
<trigger id="..." type="..." templateFolder="..." >
<containerMatcher type="..." value="..." retrieveObjectsRecursively="..." />
<matcher type="..." value="...">
<variableAssignment type="..." variable="..." value="..." />
</matcher>
</trigger>
</triggers>
</contextConfiguration>-
The attribute
typedeclares a specific type of matcher, which has to be provided by the surrounding trigger interpreter. Have a look at the plug-in’s documentation, which also provides the used trigger type for more information about valid matcher and their functionalities. -
The attribute
valuemight contain any information necessary for processing the matcher’s functionality. Have a look at the relevant plug-in’s documentation for more detail. -
The attribute
retrieveObjectsRecursively(optional boolean) states, whether the children of the input should be retrieved recursively to find matching inputs for generation.
The semantics of a container matchers are the following:
-
A
<containerMatcher>does not declare any<variableAssignment>nodes -
A
<containerMatcher>matches an input if and only if one of its enclosed elements satisfies a set of<matcher>nodes of the same<trigger> -
Inputs, which match a
<containerMatcher>will cause a generation for each enclosed element
Templates Configuration
The template configuration (templates.xml) specifies, which templates exist and under which circumstances it will be generated. There are two possible configuration styles:
-
Configure the template meta-data for each template file by template nodes
-
(since cobigen-core-v1.2.0): ConfiguretemplateScan nodesto automatically retrieve a default configuration for all files within a configured folder and possibly modify the automatically configured templates usingtemplateExtensionnodes
To get an intuition of the idea, the following will initially describe the first (more extensive) configuration style. Such an configuration root structure looks as follows:
<?xml version="1.0" encoding="UTF-8"?>
<templatesConfiguration xmlns="http://capgemini.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="1.0" templateEngine="FreeMarker">
<templates>
...
</templates>
<increments>
...
</increments>
</templatesConfiguration>The root node <templatesConfiguration> specifies two attributes. The attribute version provides further usability support and will be handled analogous to the version attribute of the context configuration. The optional attribute templateEngine specifies the template engine to be used for processing the templates (since `cobigen-core-4.0.0`). By default it is set to FreeMarker.
The node <templatesConfiguration> allows two different grouping nodes as children. First, there is the <templates> node, which groups all declarations of templates. Second, there is the <increments> node, which groups all declarations about increments.
Template Node
The <templates> node groups multiple <template> declarations, which enables further generation. Each template file should be registered at least once as a template to be considered.
<templates>
<template name="..." destinationPath="..." templateFile="..." mergeStrategy="..." targetCharset="..." />
...
</templates>A template declaration consist of multiple information:
-
The attribute
namespecifies an unique ID within the templates configuration, which will later be reused in the increment definitions. -
The attribute
destinationPathspecifies the destination path the template will be generated to. It is possible to use all variables defined by variable assignments within the path declaration using the FreeMarker syntax${variables.*}. While resolving the variable expressions, each dot within the value will be automatically replaced by a slash. This behavior is accounted for by the transformations of Java packages to paths as CobiGen has first been developed in the context of the Java world. Furthermore, the destination path variable resolution provides the following additional built-in operators analogue to the FreeMarker syntax:-
?cap_firstanalogue to FreeMarker -
?uncap_firstanalogue to FreeMarker -
?lower_caseanalogue to FreeMarker -
?upper_caseanalogue to FreeMarker -
?replace(regex, replacement)- Replaces all occurrences of the regular expressionregexin the variable’s value with the givenreplacementstring. (sincecobigen-core v1.1.0) -
?removeSuffix(suffix)- Removes the givensuffixin the variable’s value if and only if the variable’s value ends with the givensuffix. Otherwise nothing will happen. (sincecobigen-core v1.1.0) -
?removePrefix(prefix)- Analogue to?removeSuffixbut removes the prefix of the variable’s value. (sincecobigen-core v1.1.0)
-
-
The attribute
templateFiledescribes the relative path dependent on the template folder specified in the trigger to the template file to be generated. -
The attribute
mergeStrategy(optional) can be optionally specified and declares the type of merge mechanism to be used, when thedestinationPathpoints to an already existing file. CobiGen by itself just comes with amergeStrategyoverride, which enforces file regeneration in total. Additional available merge strategies have to be obtained from the different plug-in’s documentations (see here for java, XML, properties, and text). Default: not set (means not mergeable) -
The attribute
targetCharset(optional) can be optionally specified and declares the encoding with which the contents will be written into the destination file. This also includes reading an existing file at the destination path for merging its contents with the newly generated ones. Default: UTF-8
(Since version 4.1.0) It is possible to reference external template (templates defined on another trigger), thanks to using <incrementRef …> that are explained here.
Template Scan Node
(since cobigen-core-v1.2.0)
The second configuration style for template meta-data is driven by initially scanning all available templates and automatically configure them with a default set of meta-data. A scanning configuration might look like this:
<?xml version="1.0" encoding="UTF-8"?>
<templatesConfiguration xmlns="http://capgemini.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="1.2">
<templateScans>
<templateScan templatePath="templates" templateNamePrefix="prefix_" destinationPath="src/main/java"/>
</templateScans>
</templatesConfiguration>You can specify multiple <templateScan …> nodes for different templatePaths and different templateNamePrefixes.
-
The
namecan be specified to later on reference the templates found by a template-scan within an increment. (sincecobigen-core-v2.1.) -
The
templatePathspecifies the relative path from thetemplates.xmlto the root folder from which the template scan should be performed. -
The
templateNamePrefix(optional) defines a common id prefix, which will be added to all found and automatically configured templates. -
The
destinationPathdefines the root folder all found templates should be generated to, whereas the root folder will be a prefix for all found and automatically configured templates.
A templateScan will result in the following default configuration of templates. For each file found, new template will be created virtually with the following default values:
-
id: file name without.ftlextension prefixed bytemplateNamePrefixfromtemplate-scan -
destinationPath: relative file path of the file found with the prefix defined bydestinationPathfromtemplate-scan. Furthermore,-
it is possible to use the syntax for accessing and modifying variables as described for the attribute
destinationPathof the template node, besides the only difference, that due to file system restrictions you have to replace all?-signs (for built-ins) with#-signs. -
the files to be scanned, should provide their final file extension by the following file naming convention:
<filename>.<extension>.ftlThus the file extension.ftlwill be removed after generation.
-
-
templateFile: relative path to the file found -
mergeStrategy: (optional) not set means not mergeable -
targetCharset: (optional) defaults to UTF-8
(Since version 4.1.0) It is possible to reference external templateScan (templateScans defined on another trigger), thanks to using <incrementRef …> that are explained here.
Template Extension Node
(since cobigen-core-v1.2.0)
Additionally to the templateScan declaration it is easily possible to rewrite specific attributes for any scanned and automatically configured template.
TemplateExtension<templates>
<templateExtension ref="prefix_FooClass.java" mergeStrategy="javamerge" />
</templates>
<templateScans>
<templateScan templatePath="foo" templateNamePrefix="prefix_" destinationPath="src/main/java/foo"/>
</templateScans>Lets assume, that the above example declares a template-scan for the folder foo, which contains a file FooClass.java.ftl in any folder depth. Thus the template scan will automatically create a virtual template declaration with id=prefix_FooClass.java and further default configuration.
Using the templateExtension declaration above will reference the scanned template by the attribute ref and overrides the mergeStrategy of the automatically configured template by the value javamerge. Thus we are able to minimize the needed templates configuration.
(Since version 4.1.0) It is possible to reference external templateExtension (templateExtensions defined on another trigger), thanks to using <incrementRef …> that are explained here.
Increment Node
The <increments> node groups multiple <increment> nodes, which can be seen as a collection of templates to be generated. An increment will be defined by a unique id and a human readable description.
<increments>
<increment id="..." description="...">
<incrementRef ref="..." />
<templateRef ref="..." />
<templateScanRef ref="..." />
</increment>
</increments>An increment might contain multiple increments and/or templates, which will be referenced using <incrementRef …>, <templateRef …>, resp. <templateScanRef …> nodes. These nodes only declare the attribute ref, which will reference an increment, a template, or a template-scan by its id or name.
(Since version 4.1.0) An special case of <incrementRef …> is the external incrementsRef. By default, <incrementRef …> are used to reference increments defined in the same templates.xml file. So for example, we could have:
<increments>
<increment id="incA" description="...">
<incrementRef ref="incB" />
</increment>
<increment id="incB" description="...">
<templateRef .... />
<templateScan .... />
</increment>
</increments>However, if we want to reference an increment that it is not defined inside our templates.xml (an increment defined for another trigger), then we can use external incrementRef as shown below:
<increment name="..." description="...">
<incrementRef ref="trigger_id::increment_id"/>
</increment>The ref string is split using as delimiter ::. The first part of the string, is the trigger_id to reference. That trigger contains an increment_id. Currently, this functionality only works when both templates use the same kind of input file.
Java Template Logic
since cobigen-core-3.0.0 which is included in the Eclipse and Maven Plugin since version 2.0.0
In addition, it is possible to implement more complex template logic by custom Java code. To enable this feature, you can simply import the the CobiGen_Templates by clicking on Adapt Templates, turn it into a simple maven project (if it is not already) and implement any Java logic in the common maven layout (e.g. in the source folder src/main/java). Each Java class will be instantiated by CobiGen for each generation process. Thus, you can even store any state within a Java class instance during generation. However, there is currently no guarantee according to the template processing order.
As a consequence, you have to implement your Java classes with a public default (non-parameter) constructor to be used by any template. Methods of the implemented Java classes can be called within templates by the simple standard FreeMarker expression for calling Bean methods: SimpleType.methodName(param1). Until now, CobiGen will shadow multiple types with the same simple name non-deterministically. So please prevent yourself from that situation.
Finally, if you would like to do some reflection within your Java code accessing any type of the template project or any type referenced by the input, you should load classes by making use of the classloader of the util classes. CobiGen will take care of the correct classloader building including the classpath of the input source as well as of the classpath of the template project. If you use any other classloader or build it by your own, there will be no guarantee, that generation succeeds.
Template Properties
since cobigen-core-4.0.0`
Using a configuration with `template scan, you can make use of properties in templates specified in property files named cobigen.properties next to the templates. The property files are specified as Java property files. Property files can be nested in sub-folders. Properties will be resolved including property shading. Properties defined nearest to the template to be generated will take precedence.
In addition, a cobigen.properties file can be specified in the target folder root (in eclipse plugin, this is equal to the source project root). These properties take precedence over template properties specified in the template folder.
It is not allowed to override context variables in cobigen.properties specifications as we have not found any interesting use case. This is most probably an error of the template designer, CobiGen will raise an error in this case.
|
Multi module support or template target path redirects
since cobigen-core-4.0.0`
One special property you can specify in the template properties is the property `relocate. It will cause the current folder and its sub-folders to be relocated at destination path resolution time. Take the following example:
folder
- sub1
Template.java.ftl
cobigen.propertiesLet the cobigen.properties file contain the line relocate=../sub2/${cwd}. Given that, the relative destination path of Template.java.ftl will be resolved to folder/sub2/Template.java. Compare template scan configuration for more information about basic path resolution. The relocate property specifies a relative path from the location of the cobigen.properties. The ${cwd} placeholder will contain the remaining relative path from the cobigen.properties location to the template file. In this basic example it just contains Template.java.ftl, but it may even be any relative path including sub-folders of sub1 and its templates.
Given the relocate feature, you can even step out of the root path, which in general is the project/maven module the input is located in. This enables template designers to even address, e.g., maven modules located next to the module the input is coming from.
Basic Template Model
In addition to what is served by the different model builders of the different plug-ins, CobiGen provides a minimal model based on context variables as well as CobiGen properties. The following model is independent of the input format and will be served as a template model all the time:
-
variables
-
all triggered
context variablesmapped to its assigned/mapped value
-
-
all simple names of Java template logic implementation classes
-
all full qualified names of Java template logic implementation classes
-
further input related model, e.g. model from Java inputs
Plugin Mechanism
Since cobigen-core 4.1.0, we changed the plug-in discovery mechanism. So far it was necessary to register new plugins programmatically, which introduces the need to let every tool integration, i.e. for eclipse or maven, be dependent on every plug-in, which should be released. This made release cycles take long time as all plug-ins have to be integrated into a final release of maven or eclipse integration.
Now, plug-ins are automatically discovered by the Java Service Loader mechanism from the classpath. This also effects the setup of eclipse and maven integration to allow modular releases of CobiGen in future. We are now able to provide faster rollouts of bug-fixes in any of the plug-ins as they can be released completely independently.
Plug-ins
Java Plug-in
The CobiGen Java Plug-in comes with a new input reader for java artifacts, new java related trigger and matchers, as well as a merging mechanism for Java sources.
Trigger extension
The Java Plug-in provides a new trigger for Java related inputs. It accepts different representations as inputs (see Java input reader) and provides additional matching and variable assignment mechanisms. The configuration in the context.xml for this trigger looks like this:
-
type 'java'
Listing 43. Example of a java trigger definition<trigger id="..." type="java" templateFolder="..."> ... </trigger>This trigger type enables Java elements as inputs.
With the trigger you might define matchers, which restrict the input upon specific aspects:
-
type
fqn→ full qualified name matchingListing 44. Example of a java trigger definition with a full qualified name matcher<trigger id="..." type="java" templateFolder="..."> <matcher type="fqn" value="(.+)\.persistence\.([^\.]+)\.entity\.([^\.]+)"> ... </matcher> </trigger>This trigger will be enabled if the full qualified name (
fqn) of the declaring input class matches the given regular expression (value). -
type 'package' → package name of the input
Listing 45. Example of a java trigger definition with a package name matcher<trigger id="..." type="java" templateFolder="..."> <matcher type="package" value="(.+)\.persistence\.([^\.]+)\.entity"> ... </matcher> </trigger>This trigger will be enabled if the package name (
package) of the declaring input class matches the given regular expression (value). -
type 'expression'
Listing 46. Example of a java trigger definition with a package name matcher<trigger id="..." type="java" templateFolder="..."> <matcher type="expression" value="instanceof java.lang.String"> ... </matcher> </trigger>This trigger will be enabled if the expression evaluates to true. Valid expressions are
-
instanceof fqn: checks an 'is a' relation of the input type -
isAbstract: checks, whether the input type is declared abstract
Additionally, the java plugin provides the ability to match packages (containers) as follows:
-
type 'package'
Listing 47. Example of a java trigger definition with a container matcher for packages<trigger id="..." type="java" templateFolder="..."> <containerMatcher type="package" value="com\.example\.app\.component1\.persistence.entity" /> </trigger>The container matcher matches packages provided by the type
com.capgemini.cobigen.javaplugin.inputreader.to.PackageFolderwith a regular expression stated in thevalueattribute. (SeecontainerMatchersemantics to get more information aboutcontainerMatchersitself.)
Furthermore, it provides the ability to extract information from each input for further processing in the templates. The values assigned by variable assignments will be made available in template and the destinationPath of context.xml through the namespace variables.<key>. The Java Plug-in currently provides two different mechanisms:
-
type 'regex' → regular expression group
<trigger id="..." type="java" templateFolder="..."> <matcher type="fqn" value="(.+)\.persistence\.([^\.]+)\.entity\.([^\.]+)"> <variableAssignment type="regex" key="rootPackage" value="1" /> <variableAssignment type="regex" key="component" value="2" /> <variableAssignment type="regex" key="pojoName" value="3" /> </matcher> </trigger>
This variable assignment assigns the value of the given regular expression group number to the given key.
-
type 'constant' → constant parameter
<trigger id="..." type="java" templateFolder="..."> <matcher type="fqn" value="(.+)\.persistence\.([^\.]+)\.entity\.([^\.]+)"> <variableAssignment type="constant" key="domain" value="restaurant" /> </matcher> </trigger>
This variable assignment assigns the value to the key as a constant.
The CobiGen Java Plug-in implements an input reader for parsed java sources as well as for java Class<?> objects (loaded by reflection). So API user can pass Class<?> objects as well as JavaClass objects for generation. The latter depends on QDox, which will be used for parsing and merging java sources. For getting the right parsed java inputs you can easily use the JavaParserUtil, which provides static functionality to parse java files and get the appropriate JavaClass object.
Furthermore, due to restrictions on both inputs according to model building (see below), it is also possible to provide an array of length two as an input, which contains the Class<?> as well as the JavaClass object of the same class.
No matter whether you use reflection objects or parsed java classes as input, you will get the following object model for template creation:
-
classObject('Class' :: Class object of the Java input) -
POJO
-
name ('String' :: Simple name of the input class)
-
package ('String' :: Package name of the input class)
-
canonicalName('String' :: Full qualified name of the input class) -
annotations ('Map<String, Object>' :: Annotations, which will be represented by a mapping of the full qualified type of an annotation to its value. To gain template compatibility, the key will be stored with '_' instead of '.' in the full qualified annotation type. Furthermore, the annotation might be recursively defined and thus be accessed using the same type of mapping. Example
${pojo.annotations.javax_persistence_Id}) -
JavaDoc ('Map<String, Object>') :: A generic way of addressing all available JavaDoc doclets and comments. The only fixed variable is
comment(see below). All other provided variables depend on the doclets found while parsing. The value of a doclet can be accessed by the doclets name (e.g.${…JavaDoc.author}). In case of doclet tags that can be declared multiple times (currently@paramand@throws), you will get a map, which you access in a specific way (see below).-
comment ('String' :: JavaDoc comment, which does not include any doclets)
-
params ('Map<String,String> :: JavaDoc parameter info. If the comment follows proper conventions, the key will be the name of the parameter and the value being its description. You can also access the parameters by their number, as in
arg0,arg1etc, following the order of declaration in the signature, not in order of JavaDoc) -
throws ('Map<String,String> :: JavaDoc exception info. If the comment follows proper conventions, the key will be the name of the thrown exception and the value being its description)
-
-
extendedType('Map<String, Object>' :: The supertype, represented by a set of mappings (sincecobigen-javaplugin v1.1.0)-
name ('String' :: Simple name of the supertype)
-
canonicalName('String' :: Full qualified name of the supertype) -
package ('String' :: Package name of the supertype)
-
-
implementedTypes('List<Map<String, Object>>' :: A list of allimplementedTypes(interfaces) represented by a set of mappings (sincecobigen-javaplugin v1.1.0)-
interface ('Map<String, Object>' :: List element)
-
name ('String' :: Simple name of the interface)
-
canonicalName('String' :: Full qualified name of the interface) -
package ('String' :: Package name of the interface)
-
-
-
fields ('List<Map<String, Object>>' :: List of fields of the input class) (renamed since
cobigen-javaplugin v1.2.0; previously attributes)-
field ('Map<String, Object>' :: List element)
-
name ('String' :: Name of the Java field)
-
type ('String' :: Type of the Java field)
-
canonicalType('String' :: Full qualified type declaration of the Java field’s type) -
'
isId' (Deprecated::boolean:: true if the Java field or its setter or its getter is annotated with thejavax.persistence.Idannotation, false otherwise. Equivalent to${pojo.attributes[i].annotations.javax_persistence_Id?has_content}) -
JavaDoc (see
pojo.JavaDoc) -
annotations (see
pojo.annotationswith the remark, that for fields all annotations of its setter and getter will also be collected)
-
-
-
methodAccessibleFields('List<Map<String, Object>>' :: List of fields of the input class or its inherited classes, which are accessible using setter and getter methods)-
same as for field (but without JavaDoc!)
-
-
methods ('List<Map<String, Object>>' :: The list of all methods, whereas one method will be represented by a set of property mappings)
-
method ('Map<String, Object>' :: List element)
-
name ('String' :: Name of the method)
-
JavaDoc (see
pojo.JavaDoc) -
annotations (see
pojo.annotations)
-
-
-
Furthermore, when providing a Class<?> object as input, the Java Plug-in will provide additional functionalities as template methods (deprecated):
-
isAbstract(String fqn)(Checks whether the type with the given full qualified name is an abstract class. Returns a Boolean value.) (sincecobigen-javaplugin v1.1.1) (deprecated) -
isSubtypeOf(String subType, String superType)(Checks whether thesubTypedeclared by its full qualified name is a sub type of thesuperTypedeclared by its full qualified name. Equals the Java expressionsubType instanceof superTypeand so also returns a Boolean value.) (sincecobigen-javaplugin v1.1.1) (deprecated)
As stated before both inputs (Class<?> objects and JavaClass objects ) have their restrictions according to model building. In the following these restrictions are listed for both models, the ParsedJava Model which results from an JavaClass input and the ReflectedJava Model, which results from a Class<?> input.
It is important to understand, that these restrictions are only present if you work with either Parsed Model OR the Reflected Model. If you use the Maven Build Plug-in or Eclipse Plug-in these two models are merged together so that they can mutually compensate their weaknesses.
-
annotations of the input’s supertype are not accessible due to restrictions in the QDox library. So
pojo.methodAccessibleFields[i].annotationswill always be empty for super type fields. -
annotations' parameter values are available as Strings only (e.g. the Boolean value
trueis transformed into"true"). This also holds for the Reflected Model. -
fields of "supertypes" of the input
JavaClassare not available at all. Sopojo.methodAccessibleFieldswill only contain the input type’s and the direct superclass’s fields. -
[resolved, since
cobigen-javaplugin 1.3.1] field types of supertypes are always canonical. Sopojo.methodAccessibleFields[i].typewill always provide the same value aspojo.methodAccessibleFields[i].canonicalType(e.g.java.lang.Stringinstead of the expectedString) for super type fields.
-
annotations' parameter values are available as Strings only (e.g. the Boolean value
trueis transformed into"true"). This also holds for the Parsed Model. -
annotations are only available if the respective annotation has
@Retention(value=RUNTIME), otherwise the annotations are to be discarded by the compiler or by the VM at run time. For more information see RetentionPolicy. -
information about generic types is lost. E.g. a field’s/ methodAccessibleField’s type for
List<String>can only be provided asList<?>.
Merger extensions
The Java Plug-in provides two additional merging strategies for Java sources, which can be configured in the templates.xml:
-
Merge strategy
javamerge(merges two Java resources and keeps the existing Java elements on conflicts) -
Merge strategy
javamerge_override(merges two Java resources and overrides the existing Java elements on conflicts)
In general merging of two Java sources will be processed as follows:
Precondition of processing a merge of generated contents and existing ones is a common Java root class resp. surrounding class. If this is the case this class and all further inner classes will be merged recursively. Therefore, the following Java elements will be merged and conflicts will be resolved according to the configured merge strategy:
-
extendsandimplementsrelations of a class: Conflicts can only occur for the extends relation. -
Annotations of a class: Conflicted if an annotation declaration already exists.
-
Fields of a class: Conflicted if there is already a field with the same name in the existing sources. (Will be replaced / ignored in total, also including annotations)
-
Methods of a class: Conflicted if there is already a method with the same signature in the existing sources. (Will be replaced / ignored in total, also including annotations)
Property Plug-in
The CobiGen Property Plug-in currently only provides different merge mechanisms for documents written in Java property syntax.
Merger extensions
There are two merge strategies for Java properties, which can be configured in the templates.xml:
-
Merge strategy
propertymerge(merges two properties documents and keeps the existing properties on conflicts) -
Merge strategy
propertymerge_override(merges two properties documents and overrides the existing properties on conflicts)
Both documents (base and patch) will be parsed using the Java 7 API and will be compared according their keys. Conflicts will occur if a key in the patch already exists in the base document.
XML Plug-in
The CobiGen XML Plug-in comes with an input reader for XML artifacts, XML related trigger and matchers and provides different merge mechanisms for XML result documents.
Trigger extension
(since cobigen-xmlplugin v2.0.0)
The XML Plug-in provides a trigger for XML related inputs. It accepts XML documents as input (see XML input reader) and provides additional matching and variable assignment mechanisms. The configuration in the context.xml for this trigger looks like this:
-
type 'xml'
Listing 48. Example of a XML trigger definition.<trigger id="..." type="xml" templateFolder="..."> ... </trigger>This trigger type enables XML documents as inputs.
-
type
xpathListing 49. Example of axpathtrigger definition.<trigger id="..." type="xpath" templateFolder="..."> ... </trigger>This trigger type enables XML documents as container inputs, which consists of several sub-documents.
A ContainerMatcher check if the input is a valid container.
-
xpath: type:xpathListing 50. Example of a XML trigger definition with a node name matcher.<trigger id="..." type="xml" templateFolder="..."> <containerMatcher type="xpath" value="./uml:Model//packagedElement[@xmi:type='uml:Class']"> ... </matcher> </trigger>Before applying any Matcher, this
containerMatcherchecks if the XML file contains a nodeuml:Modelwith a childnodepackagedElementwhich contains an attributexmi:typewith the valueuml:Class.
With the trigger you might define matchers, which restrict the input upon specific aspects:
-
XML: type
nodename→ document’s root name matchingListing 51. Example of a XML trigger definition with a node name matcher<trigger id="..." type="xml" templateFolder="..."> <matcher type="nodename" value="\D\w*"> ... </matcher> </trigger>This trigger will be enabled if the root name of the declaring input document matches the given regular expression (
value). -
xpath: type:xpath→ matching a node with axpathvalueListing 52. Example of axpathtrigger definition with axpathmatcher.<trigger id="..." type="xml" templateFolder="..."> <matcher type="xpath" value="/packagedElement[@xmi:type='uml:Class']"> ... </matcher> </trigger>This trigger will be enabled if the XML file contains a node
/packagedElementwhere thexmi:typeproperty equalsuml:Class.
Furthermore, it provides the ability to extract information from each input for further processing in the templates. The values assigned by variable assignments will be made available in template and the destinationPath of context.xml through the namespace variables.<key>. The XML Plug-in currently provides only one mechanism:
-
type 'constant' → constant parameter
<trigger id="..." type="xml" templateFolder="..."> <matcher type="nodename" value="\D\w*"> <variableAssignment type="constant" key="domain" value="restaurant" /> </matcher> </trigger>
This variable assignment assigns the value to the key as a constant.
The CobiGen XML Plug-in implements an input reader for parsed XML documents. So API user can pass org.w3c.dom.Document objects for generation. For getting the right parsed XML inputs you can easily use the xmlplugin.util.XmlUtil, which provides static functionality to parse XML files or input streams and get the appropriate Document object.
Due to the heterogeneous structure an XML document can have, the XML input reader does not always create exactly the same model structure (in contrast to the java input reader). For example the model’s depth differs strongly, according to it’s input document. To allow navigational access to the nodes, the model also depends on the document’s element’s node names. All child elements with unique names, are directly accessible via their names. In addition it is possible to iterate over all child elements with held of the child list Children. So it is also possible to access child elements with non unique names.
The XML input reader will create the following object model for template creation (EXAMPLEROOT, EXAMPLENODE1, EXAMPLENODE2, EXAMPLEATTR1,… are just used here as examples. Of course they will be replaced later by the actual node or attribute names):
-
~EXAMPLEROOT~('Map<String, Object>' :: common element structure)-
_nodeName_('String' :: Simple name of the root node) -
_text_('String' :: Concatenated text content (PCDATA) of the root node) -
TextNodes('List<String>' :: List of all the root’s text node contents) -
_at_~EXAMPLEATTR1~('String' :: String representation of the attribute’s value) -
_at_~EXAMPLEATTR2~('String' :: String representation of the attribute’s value) -
_at_…
-
Attributes ('List<Map<String, Object>>' :: List of the root’s attributes
-
at ('Map<String, Object>' :: List element)
-
_attName_ ('String' :: Name of the attribute) -
_attValue_ ('String' :: String representation of the attribute’s value)
-
-
-
Children ('List<Map<String, Object>>' :: List of the root’s child elements
-
child ('Map<String, Object>' :: List element)
-
…common element sub structure…
-
-
-
~EXAMPLENODE1~('Map<String, Object>' :: One of the root’s child nodes)-
…common element structure…
-
-
~EXAMPLENODE2~('Map<String, Object>' :: One of the root’s child nodes)-
…common element sub structure…
-
~EXAMPLENODE21~('Map<String, Object>' :: One of the nodes' child nodes)-
…common element structure…
-
-
~EXAMPLENODE…~
-
-
~EXAMPLENODE…~
-
In contrast to the java input reader, this XML input reader does currently not provide any additional template methods.
Merger extensions
The XML plugin uses the LeXeMe merger library to produce semantically correct merge products. The merge strategies can be found in the MergeType enum and can be configured in the templates.xml as a mergeStrategy attribute:
-
mergeStrategy xmlmergeListing 53. Example of a template using themergeStrategyxmlmerge<templates> <template name="..." destinationPath="..." templateFile="..." mergeStrategy="xmlmerge"/> </templates>
Currently only the document types included in LeXeMe are supported. On how the merger works consult the LeXeMe Wiki.
Text Merger Plug-in
The Text Merger Plug-in enables merging result free text documents to existing free text documents. Therefore, the algorithms are also very rudimentary.
Merger extensions
There are currently three main merge strategies that apply for the whole document:
-
merge strategy
textmerge_append(appends the text directly to the end of the existing document) _Remark_: If no anchors are defined, this will simply append the patch. -
merge strategy
textmerge_appendWithNewLine(appends the text after adding a new line break to the existing document) _Remark_: empty patches will not result in appending a new line any more since v1.0.1 Remark: Only suitable if no anchors are defined, otherwise it will simply act astextmerge_append -
merge strategy
textmerge_override(replaces the contents of the existing file with the patch) _Remark_: If anchors are defined, override is set as the defaultmergestrategyfor every text block if not redefined in an anchor specification.
Anchor functionality
If a template contains text that fits the definition of anchor:${documentpart}:${mergestrategy}:anchorend or more specifically the regular expression (.*)anchor:([:]+):(newline_)?([:]+)(_newline)?:anchorend\\s*(\\r\\n|\\r|\\n), some additional functionality becomes available about specific parts of the incoming text and the way it will be merged with the existing text. These anchors always change things about the text to come up until the next anchor, text before it is ignored.
If no anchors are defined, the complete patch will be appended depending on your choice for the template in the file templates.xml.
Anchors should always be defined as a comment of the language the template results in, as you do not want them to appear in your readable version, but cannot define them as FreeMarker comments in the template, or the merger will not know about them. Anchors will also be read when they are not comments due to the merger being able to merge multiple types of text-based languages, thus making it practically impossible to filter for the correct comment declaration. That is why anchors have to always be followed by line breaks. That way there is a universal way to filter anchors that should have anchor functionality and ones that should appear in the text. Remark: If the resulting language has closing tags for comments, they have to appear in the next line. Remark: If you do not put the anchor into a new line, all the text that appears before it will be added to the anchor.
In general, ${documentpart} is an id to mark a part of the document, that way the merger knows what parts of the text to merge with which parts of the patch (e.g. if the existing text contains anchor:table:${}:anchorend that part will be merged with the part tagged anchor:table:${}:anchorend of the patch).
If the same documentpart is defined multiple times, it can lead to errors, so instead of defining table multiple times, use table1, table2, table3 etc.
If a ${documentpart} is defined in the document but not in the patch and they are in the same position, it is processed in the following way: If only the documentparts header, test and footer are defined in the document in that order, and the patch contains header, order and footer, the resulting order will be header, test, order then footer.
The following documentparts have default functionality:
-
anchor:header:${mergestrategy}:anchorendmarks the beginning of a header, that will be added once when the document is created, but not again. Remark: This is only done once, if you haveheaderin another anchor, it will be ignored -
anchor:footer:${mergestrategy}:anchorendmarks the beginning of a footer, that will be added once when the document is created, but not again. Once this is invoked, all following text will be included in the footer, including other anchors.
MergestrategiesMergestrategies are only relevant in the patch, as the merger is only interested in how text in the patch should be managed, not how it was managed in the past.
-
anchor:${documentpart}::anchorendwill use the merge strategy fromtemplates.xml, see Merger-Extensions. -
anchor:${}:${mergestrategy}_newline:anchorendoranchor:${}:newline_${mergestrategy}:anchorendstates that a new line should be appended before or after this anchors text, depending on where the newline is (before or after themergestrategy).anchor:${documentpart}:newline:anchorendputs a new line after the anchors text. Remark: Only works with appending strategies, not merging/replacing ones. These strategies currently include:appendbefore,append/appendafter -
anchor:${documentpart}:override:anchorendmeans that the new text of thisdocumentpartwill replace the existing one completely -
anchor:${documentpart}:appendbefore:anchorendoranchor:${documentpart}:appendafter:anchorend/anchor:${documentpart}:append:anchorendspecifies whether the text of the patch should come before the existing text or after.
Usage Examples
Below you can see how a file with anchors might look like (using AsciiDoc comment tags), with examples of what you might want to use the different functions for.
// anchor:header:append:anchorend Table of contents Introduction/Header // anchor:part1:appendafter:anchorend Lists Table entries // anchor:part2:nomerge:anchorend Document Separators AsciiDoc table definitions // anchor:part3:override:anchorend Anything that you only want once but changes from time to time // anchor:footer:append:anchorend Copyright Info Imprint
In this section you will see a comparison on what files look like before and after merging
// anchor:part:override:anchorend Lorem Ipsum
// anchor:part:override:anchorend Dolor Sit
// anchor:part:override:anchorend Dolor Sit
// anchor:part:append:anchorend Lorem Ipsum // anchor:part2:appendafter:anchorend Lorem Ipsum // anchor:part3:appendbefore:anchorend Lorem Ipsum
// anchor:part:append:anchorend Dolor Sit // anchor:part2:appendafter:anchorend Dolor Sit // anchor:part3:appendbefore:anchorend Dolor Sit
// anchor:part:append:anchorend Lorem Ipsum Dolor Sit // anchor:part2:appendafter:anchorend Lorem Ipsum Dolor Sit // anchor:part3:appendbefore:anchorend Dolor Sit Lorem Ipsum
// anchor:part:newline_append:anchorend Lorem Ipsum // anchor:part:append_newline:anchorend Lorem Ipsum (end of file)
// anchor:part:newline_append:anchorend Dolor Sit // anchor:part:append_newline:anchorend Dolor Sit (end of file)
// anchor:part:newline_append:anchorend Lorem Ipsum Dolor Sit // anchor:part:append_newline:anchorend Lorem Ipsum Dolor Sit (end of file)
Error List
-
If there are anchors in the text, but either base or patch do not start with one, the merging process will be aborted, as text might go missing this way.
-
Using
_newlineornewline_withmergestrategiesthat don’t support it , likeoverride, will abort the merging process. See <<`mergestrategies`,Merge Strategies>> →2 for details. -
Using undefined
mergestrategieswill abort the merging process. -
Wrong anchor definitions, for example
anchor:${}:anchorendwill abort the merging process, see <<`anchordef`,Anchor Definition>> for details.
JSON Plug-in
At the moment the plug-in can be used for merge generic JSON files depending on the merge strategy defined at the templates.
Merger extensions
There are currently these merge strategies:
Generic JSON Merge
-
merge strategy
jsonmerge(add the new code respecting the existent is case of conflict) -
merge strategy
jsonmerge_override(add the new code overwriting the existent in case of conflict)-
JsonArray’swill be ignored / replaced in total -
JsonObjectsin conflict will be processed recursively ignoring adding non existent elements.
-
Merge Process
The merge process will be:
-
Add non existent JSON Objects from patch file to base file.
-
For existent object in both files, will add non existent keys from patch to base object. This process will be done recursively for all existent objects.
-
For JSON Arrays existent in both files, the arrays will be just concatenated.
TypeScript Plug-in
The TypeScript Plug-in enables merging result TS files to existing ones. This plug-in is used at the moment for generate an Angular2 client with all CRUD functionalities enabled. The plug-in also generates i18n functionality just appending at the end of the word the ES or EN suffixes, to put into the developer knowledge that this words must been translated to the correspondent language. Currently, the generation of Angular2 client requires an ETO java object as input so, there is no need to implement an input reader for ts artifacts for the moment.
Trigger Extensions
As for the Angular2 generation the input is a java object, the trigger expressions (including matchers and variable assignments) are implemented as Java.
Merger extensions
This plugin uses the TypeScript Merger to merge files. There are currently two merge strategies:
-
merge strategy
tsmerge(add the new code respecting the existing is case of conflict) -
merge strategy
tsmerge_override(add the new code overwriting the existent in case of conflict)
<<<<<<< HEAD
The merge algorithm mainly handles the following AST nodes:
-
ImportDeclaration-
Will add non existent imports whatever the merge strategy is.
-
For different imports from same module, the import clauses will be merged.
import { a } from 'b'; import { c } from 'b'; //Result import { a, c } from 'b';
-
-
ClassDeclaration-
Adds non existent base properties from patch based on the name property.
-
Adds non existent base methods from patch based on the name signature.
-
Adds non existent annotations to class, properties and methods.
-
-
PropertyDeclaration-
Adds non existent decorators.
-
Merge existent decorators.
-
With override strategy, the value of the property will be replaced by the patch value.
-
-
MethodDeclaration-
With override strategy, the body will be replaced.
-
The parameters will be merged.
-
-
ParameterDeclaration-
Replace type and modifiers with override merge strategy, adding non existent from patch into base.
-
-
ConstructorDeclaration-
Merged in the same way as Method is.
-
-
FunctionDeclaration-
Merged in the same way as Method is.
-
Input reader
The TypeScript input reader is based on the one that the TypeScript merger uses. The current extensions are additional module fields giving from which library any entity originates.
module: null specifies a standard entity or type as string or number.
To get a first impression of the created object after parsing, let us start with analyzing a small example, namely the parsing of a simple TypeORM model written in TypeScript.
import {Entity, PrimaryGeneratedColumn, Column} from "typeorm";
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
firstName: string;
@Column()
lastName: string;
@Column()
age: number;
}The returned object has the following structure
{
"importDeclarations": [
{
"module": "typeorm",
"named": [
"Entity",
"PrimaryGeneratedColumn",
"Column"
],
"spaceBinding": true
}
],
"classes": [
{
"identifier": "User",
"modifiers": [
"export"
],
"decorators": [
{
"identifier": {
"name": "Entity",
"module": "typeorm"
},
"isCallExpression": true
}
],
"properties": [
{
"identifier": "id",
"type": {
"name": "number",
"module": null
},
"decorators": [
{
"identifier": {
"name": "PrimaryGeneratedColumn",
"module": "typeorm"
},
"isCallExpression": true
}
]
},
{
"identifier": "firstName",
"type": {
"name": "string",
"module": null
},
"decorators": [
{
"identifier": {
"name": "Column",
"module": "typeorm"
},
"isCallExpression": true
}
]
},
{
"identifier": "lastName",
"type": {
"name": "string",
"module": null
},
"decorators": [
{
"identifier": {
"name": "Column",
"module": "typeorm"
},
"isCallExpression": true
}
]
},
{
"identifier": "age",
"type": {
"name": "number",
"module": null
},
"decorators": [
{
"identifier": {
"name": "Column",
"module": "typeorm"
},
"isCallExpression": true
}
]
}
]
}
]
}If we only consider the first level of the JSON response, we spot two lists of imports and classes, providing information about the only import statement and the only User class, respectively. Moving one level deeper we observe that:
-
Every import statement is translated to an import declaration entry in the declarations list, containing the module name, as well as a list of entities imported from the given module.
-
Every class entry provides besides the class identifier, its decoration(s), modifier(s), as well as a list of properties that the original class contains.
Note that, for each given type, the module from which it is imported is also given as in
"identifier": {
"name": "Column",
"module": "typeorm"
}Returning to the general case, independently from the given TypeScript file, an object having the following Structure will be created.
-
importDeclarations: A list of import statement as described above -
exportDeclarations: A list of export declarations -
classes: A list of classes extracted from the given file, where each entry is full of class specific fields, describing its properties and decorator for example. -
interfaces: A list of interfaces. -
variables: A list of variables. -
functions: A list of functions. -
enums: A list of enumerations.
HTML Plug-in
The HTML Plug-in enables merging result HTML files to existing ones. This plug-in is used at the moment for generate an Angular2 client. Currently, the generation of Angular2 client requires an ETO java object as input so, there is no need to implement an input reader for ts artifacts for the moment.
Trigger Extensions
As for the Angular2 generation the input is a java object, the trigger expressions (including matchers and variable assignments) are implemented as Java.
Merger extensions
There are currently two merge strategies:
-
merge strategy
html-ng*(add the new code respecting the existing is case of conflict) -
merge strategy
html-ng*_override(add the new code overwriting the existent in case of conflict)
The merging of two Angular2 files will be processed as follows:
The merge algorithm handles the following AST nodes:
-
md-nav-list -
a -
form -
md-input-container -
input -
name(for name attribute) -
ngIf
| Be aware, that the HTML merger is not generic and only handles the described tags needed for merging code of a basic Angular client implementation. For future versions, it is planned to implement a more generic solution. |
OpenAPI Plug-in
The OpenAPI Plug-in enables the support for Swagger files that follows the OpenAPI 3.0 standard as input for CobiGen. Until now, CobiGen was thought to follow a "code first" generation, with this plugin, now it can also follow the "contract first" strategy
-
Code First
-
Generating from a file with code (Java/XML code in our case)
-
-
Contract First
-
Generation from a full definition file (Swagger in this case). This file contains all the information about entities, operations, etc…
-
| If you are not a CobiGen developer, you will be more interested in usage. |
Trigger Extensions
The OpenAPI Plug-in provides a new trigger for Swagger OpenAPI 3.0 related inputs. It accepts different representations as inputs (see OpenAPI input reader) and provides additional matching and variable assignment mechanisms. The configuration in the context.xml for this trigger looks like this:
-
type
openapiListing 63. Example of a OpenAPI trigger definition<trigger id="..." type="openapi" templateFolder="..."> ... </trigger>This trigger type enables OpenAPI elements as inputs.
With the trigger you might define matchers, which restrict the input upon specific aspects:
-
type 'element' → An object
This trigger will be enabled if the element (Java Object) of the input file is and EntityDef (value).
Additionally, the java plugin provides the ability to match packages (containers) as follows:
-
type 'element'
The container matcher matches elements as Java Objects, in this case will be always an OpenAPIFile object. (See containerMatcher semantics to get more information about containerMatchers itself.)
Furthermore, it provides the ability to extract information from each input for further processing in the templates. The values assigned by variable assignments will be made available in template and the destinationPath of context.xml through the namespace variables.<key>. The OpenAPI Plug-in currently provides two different mechanisms:
-
type 'constant' → constant parameter
<trigger id="..." type="openapi" templateFolder="..."> <containerMatcher type="element" value="OpenApiFile"/> <matcher type="element" value="EntityDef"> <variableAssignment type="constant" key="rootPackage" value="com.capgemini.demo" /> </matcher> </trigger>
This variable assignment assigns the value of the given regular expression group number to the given key.
In this case, the constant type variableAssignment is used to specify the root package where the generate will place the files generated.
-
type 'extension' → Extraction of the info extensions and the extensions of each entity. (the tags that start with
"x-…").<trigger id="..." type="openapi" templateFolder="..."> <containerMatcher type="element" value="OpenApiFile"/> <matcher type="element" value="EntityDef"> <variableAssignment type="extension" key="testingAttribute" value="x-test"/> <variableAssignment type="extension" key="rootPackage" value="x-rootpackage"/> <variableAssignment type="extension" key="globalVariable" value="x-global"/> </matcher> </trigger>
The 'extension' variable assignment tries to find 'extensions' (tags that start with "x-…") on the 'info'
part of your file and on the extensions of each entity. value is the extension that our plug-in will try to find on your OpenAPI file. The result will
be stored in the variable key.
As you will see on the figure below, there are two types of variables: The global ones, that are defined on the 'info' part of the file, and the local ones, that are defined inside each entity.
Therefore, if you want to define the root package, then you will have to declare it on the 'info' part. That way, all your entities will be generated under the same root package (e.g. com.devonfw.project).
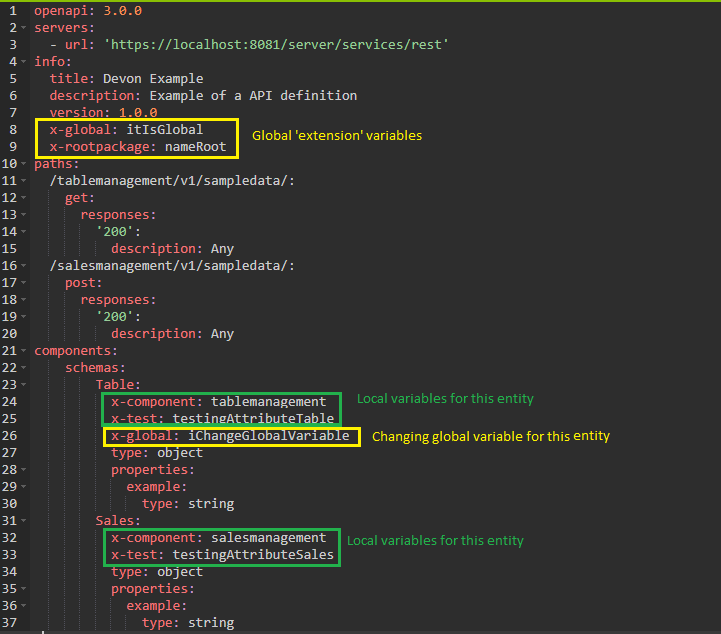
If no extension with that name was found, then an empty string will be assigned. In the case of not defining the root package, then the code will be generated into src/main/java.
-
type 'property' → property of the Java Object
<trigger id="..." type="openapi" templateFolder="..."> <containerMatcher type="element" value="OpenApiFile"/> <matcher type="element" value="EntityDef"> <variableAssignment type="property" key="entityName" value="name" /> </matcher> </trigger>
The 'property' variable assignment tries to find the property value of the entities defined on the schema.
The value is assigned to the key. The current properties that you will able to get are:
-
ComponentDef component: It is an object that stores the configuration of an devon4j component. Its only property isList<PathDef> pathswhich contains the paths as the ones shown here. -
String componentName: Stores the name of thex-componenttag for this entity. -
String name: Name of this entity (as shown on the example above). -
String description: Description of this entity. -
List<PropertyDef> properties: List containing all the properties of this entity.PropertyDefis an object that has the next properties:-
String name.
-
String type.
-
String format.
-
String description.
-
Boolean
isCollection. -
Boolean
isEntity. -
Boolean required.
-
Map<String, Object> constraints
-
If no property with that name was found, then it will be set to null.
<trigger id="..." type="openapi" templateFolder="...">
<containerMatcher type="element" value="OpenApiFile">
<matcher type="element" value="EntityDef">
<variableAssignment type="constant" key="rootPackage" value="com.capgemini.demo" />
<variableAssignment type="property" key="component" value="componentName" />
<variableAssignment type="property" key="entityName" value="name" />
</matcher>
</trigger>Input reader
The CobiGen OpenAPI Plug-in implements an input reader for OpenAPI 3.0 files. The XML input reader will create the following object model for template creation:
-
model ('Map<String, Object>' :: common element structure)
-
header (
HeaderDef:: Definition of the header found at the top of the file) -
name ('String' :: Name of the current Entity)
-
componentName('String' :: name of the component the entity belongs to) -
component (
ComponentDef:: Full definition of the component that entity belongs to) -
description ('String' :: Description of the Entity)
-
properties (
List<PropertyDef>:: List of properties the entity has) -
relationShips(List<RelationShip>:: List of Relationships the entity has)
-
-
HeaderDef('Map<String, Object>' :: common element structure)-
info (
InfoDef:: Definition of the info found in the header) -
servers (
List<ServerDef>:: List of servers the specification uses)
-
-
InfoDef('Map<String, Object>' :: common element structure)-
title ('String' :: The title of the specification)
-
description ('String' :: The description of the specification)
-
-
ServerDef('Map<String, Object>' :: common element structure)-
URI('String' :: String representation of the Server location) -
description ('String' :: description of the server)
-
-
ComponentDef('Map<String, Object>' :: common element structure)-
paths (
List<PathDef>:: List of services for this component)
-
-
PropertyDef('Map<String, Object>' :: common element structure)-
name ('String' :: Name of the property)
-
type ('String' :: type of the property)
-
format ('String' :: format of the property (i.e. int64))
-
isCollection(boolean:: true if the property is a collection, false by default) -
isEntity(boolean:: true if the property refers to another entity, false by default) -
sameComponent(boolean:: true if the entity that the property refers to belongs to the same component, false by default) -
description ('String' :: Description of the property)
-
required (
boolean:: true if the property is set as required) -
constraints ('Map<String, Object>')
-
-
RelationShip('Map<String, Object>' :: common element structure)-
type ('String' :: type of the relationship (
OneToOne,ManyToMany, etc…)) -
entity ('String' :: destination entity name)
-
sameComponent(boolean:: true if the destination entity belongs to the same component of the source entity, false by default) -
unidirectional(boolean:: true if the relationship is unidirectional, false by default)
-
-
PathDef('Map<String, Object>' :: common element structure)-
rootComponent('String' :: the first segment of the path) -
version ('String' :: version of the service)
-
pathURI('String' :: URI of the path, the segment after the version) -
operations (
List<OperationDef>:: List of operations for this path)
-
-
OperationDef('Map<String, Object>' :: common element structure)-
type ('String' :: type of the operation (GET, PUT, etc…))
-
parameters (
List<ParameterDef>:: List of parameters) -
operationId('String' :: name of the operation prototype) -
description ('String' ::
JavaDocDescription of the operation) -
summary (
List<PropertyDef>::JavaDocoperation Summary) -
tags ('List<String>' :: List of different tags)
-
responses (
List<ResponseDef>:: Responses of the operation)
-
-
ParameterDef('Map<String, Object>' :: common element structure)-
isSearchCriteria(boolean:: true if the response is anSearchCriteriaobject) -
inPath(boolean:: true if this parameter is contained in the request path) -
inQuery(boolean:: true if this parameter is contained in a query) -
isBody(boolean:: true if this parameter is a response body) -
inHeader(boolean:: true if this parameter is contained in a header) -
mediaType('String' :: String representation of the media type of the parameter)
-
-
ResponseDef('Map<String, Object>' :: common element structure)-
isArray(boolean:: true if the type of the response is an Array) -
isPaginated(boolean:: true if the type of the response is paginated) -
isVoid(boolean:: true if there is no type/an empty type) -
isEntity(boolean:: true if the type of the response is an Entity) -
entityRef(EntityDef:: IncompleteEntityDefcontaining the name and properties of the referenced Entity) -
type ('String' :: String representation of the attribute’s value)
-
code ('String' :: String representation of the HTTP status code)
-
mediaTypes('List<String>' :: List of media types that can be returned) -
description ('String' :: Description of the response)
-
Merger extensions
This plugin only provides an input reader, there is no support for OpenAPI merging. Nevertheless, the files generated from an OpenAPI file will be Java, XML, JSON, TS, etc… so,
for each file to be generated defined at templates.xml, must set the mergeStrategy for the specific language (javamerge, javamerge_override, jsonmerge, etc…)
<templates>
...
<templateExtension ref="${variables.entityName}.java" mergeStrategy="javamerge"/>
...
<templateExtension ref="${variables.entityName}dataGrid.component.ts" mergeStrategy="tsmerge"/>
...
<templateExtension ref="en.json" mergeStrategy="jsonmerge"/>
</templates>Usage
OpenAPI 3.0 contract fileThe Swagger file must follow the OpenAPI 3.0 standard to be readable by CobiGen, otherwise and error will be thrown.
A full documentation about how to follow this standard can be found Swagger3 Docs.
The Swagger file must be at the core folder of your devon4j project, like shown below:

To be compatible with CobiGen and devon4j, it must follow some specific configurations. This configurations allows us to avoid redundant definitions as SearchCriteria and PaginatedList objects are used at the services definitions.
-
Just adding the tags property at the end of the service definitions with the items `SearchCriteria` and/or paginated put into CobiGen knowledge that an standard devon4j
SearchCriteriaand/orPaginateListToobject must be generated. That way, the Swagger file will be easier to write and even more understandable. -
The path must start with the component name, and define an
x-componenttag with the component name. That way this service will be included into the component services list.
/componentnamemanagement/v1/entityname/customOperation/:
x-component: componentnamemanagement
post:
summary: 'Summary of the operation'
description: Description of the operation.
operationId: customOperation
responses:
'200':
description: Description of the response.
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/EntityName'
requestBody:
$ref: '#/components/requestBodies/EntityName'
tags:
- searchCriteria
- paginatedThat way, CobiGen will be able to generate the endpoint (REST service) customOperation on componentmanagement. If you do not specify the component to generate to (the x-component tag) then this service will not be taken into account for generation.
In previous CobiGen versions, we were able to generate code from a contract-first OpenAPI specification only when we defined components like the following:
components:
schemas:
Shop:
x-component: shopmanagement
description: Entity definition of Shop
type: object
properties:
shopExample:
type: string
maxLength: 100
minLength: 5
uniqueItems: trueWe could not generate services without the definition of those components.
In our current version, we have overcome it, so that now we are able to generate all the services independently. You just need to add an x-component tag with the name of the component that will make use of that service. See here.
An small OpenAPI example defining only services can be found below:
openapi: 3.0.0
servers:
- url: 'https://localhost:8081/server/services/rest'
description: Just some data
info:
title: Devon Example
description: Example of a API definition
version: 1.0.0
x-rootpackage: com.capgemini.spoc.openapi
paths:
/salemanagement/v1/sale/{saleId}:
x-component: salemanagement
get:
operationId: findSale
parameters:
- name: saleId
in: path
required: true
description: The id of the pet to retrieve
schema:
type: string
responses:
'200':
description: Any
/salemanagement/v1/sale/{bla}:
x-component: salemanagement
get:
operationId: findSaleBla
parameters:
- name: bla
in: path
required: true
schema:
type: integer
format: int64
minimum: 10
maximum: 200
responses:
'200':
description: AnyThen, the increment that you need to select for generating those services is Crud devon4ng Service based Angular:

This example yaml file can be download from here.
| As you will see on the file, "x-component" tags are obligatory if you want to generate components (entities). They have to be defined for each one. In addition, you will find the global variable "x-rootpackage" that are explained <<,here>>. |
openapi: 3.0.0
servers:
- url: 'https://localhost:8081/server/services/rest'
description: Just some data
info:
title: Devon Example
description: Example of a API definition
version: 1.0.0
x-rootpackage: com.devonfw.angular.test
paths:
/shopmanagement/v1/shop/{shopId}:
x-component: shopmanagement
get:
operationId: findShop
parameters:
- name: shopId
in: path
required: true
schema:
type: integer
format: int64
minimum: 0
maximum: 50
responses:
'200':
description: Any
content:
application/json:
schema:
$ref: '#/components/schemas/Shop'
text/plain:
schema:
type: string
'404':
description: Not found
/salemanagement/v1/sale/{saleId}:
x-component: salemanagement
get:
operationId: findSale
parameters:
- name: saleId
in: path
required: true
description: The id of the pet to retrieve
schema:
type: string
responses:
'200':
description: Any
/salemanagement/v1/sale/:
x-component: salemanagement
post:
responses:
'200':
description: Any
requestBody:
$ref: '#/components/requestBodies/SaleData'
tags:
- searchCriteria
/shopmanagement/v1/shop/new:
x-component: shopmanagement
post:
responses:
'200':
description: Any
requestBody:
$ref: '#/components/requestBodies/ShopData'
components:
schemas:
Shop:
x-component: shopmanagement
description: Entity definition of Shop
type: object
properties:
shopExample:
type: string
maxLength: 100
minLength: 5
uniqueItems: true
sales:
type: array # Many to One relationship
items:
$ref: '#/components/schemas/Sale'
Sale:
x-component: salemanagement
description: Entity definition of Shop
type: object
properties:
saleExample:
type: number
format: int64
maximum: 100
minimum: 0
required:
- saleExample
requestBodies:
ShopData:
content:
application/json:
schema:
$ref: '#/components/schemas/Shop'
required: true
SaleData:
content:
application/json:
schema:
$ref: '#/components/schemas/Sale'
required: true