
Architecture
Introduction
The devonfw platform provides a solution to building applications which combine best-in-class frameworks and libraries as well as industry proven practices and code conventions. It massively speeds up development, reduces risks and helps you to deliver better results. When it comes to achieving these objectives, having a very clear and well-defined architecture is critical.
This guide will teach you the fundamentals of the suggested architecture, which is based on layers in order to develop the best possible quality software, applying design patterns, coding principles and the best practices known in the industry.
Before getting started, it’s helpful to understand a few key ideas that will come in handy.
What is code quality?
Quality is a subjective concept; one person may regard something as high quality while another does not. So, how can we tell whether a piece of code is of good quaility or not? Different teams may use different definitions, based on context, but there are five common standard metrics used to measure it:
-
Reliability: Measures the probability of a system running without failure over a specific period of time. It relates to the number of defects and availability of the software.
-
Maintainability: Measures how easily software can be maintained. It relates to the size, consistency, structure, and complexity of the codebase.
-
Testability: Measures how well the software supports testing efforts. It relies on how well you can control, observe, isolate, and automate testing, among other factors.
-
Portability: Measures how usable the same software is in different environments.
-
Reusability: Measures whether existing assets, such as code, can be used again. Assets are more easily reused if they have characteristics such as modularity or loose coupling.
What is architecture quality?
Using a well-defined architecture is essential to ensure quality development of long-lived business applications as well as applications with complex behavior.
-
Scalability: Software scalability is the ability to grow or shrink a piece of software to meet changing demands on a business.
-
Loose coupling: Loose coupling is an approach to interconnecting the components in a system or network so that they are weakly associated and easily replaceable.
-
Developer friendly: A clean, structured and well-documented architecture makes reading and understanding the code much easier to developers.
Onion Architecture
As the name suggests, the proposed architecture makes use of cooperating components called layers, just like an onion.
It is important to understand the difference between layers and tiers. Layers describe the logical groupings of the functionality and components in an application; whereas tiers describe the physical distribution of the functionality and components on separate servers, computers, networks, or remote locations. Although both layers and tiers use the same set of names (presentation, business, services, and data), remember that only tiers imply a physical separation. It is quite common to locate more than one layer on the same physical machine (the same tier). You can think of the term tier as referring to physical distribution patterns such as two-tier, three-tier, and n-tier.
MSDN Microsoft
The main objective is to control the coupling in such way that the high-level modules do not rely on low level ones, but rather on abstractions of them. Components in a loosely coupled system can be replaced with alternative implementations that provide the same services.
This principle is called Dependency Injection. To implement it, we will also be using the Dependency Injection pattern available in .NET Core.
Domain Layer
This type of architecture also follows Domain-Driven-Design (DDD) principles, so we can find the Domain Model in the very center. It represents the state and behavior combination that models truth for the organization.
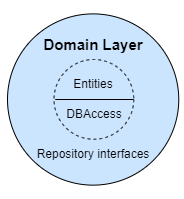
As shown in the diagram, the entities and the database context that provides access to an external database are placed in the core of the application. Repository contracts (interfaces) that provide object saving and retrieving behavior can also be found in this layer.
The Domain Model is only coupled to itself, so it doesn’t have any dependency on other application layers.
Data Layer
The first layer around the Domain Model is typically the one that orchestrates the data obtained from the database, betweeen the Domain Layer and the Business Layer.
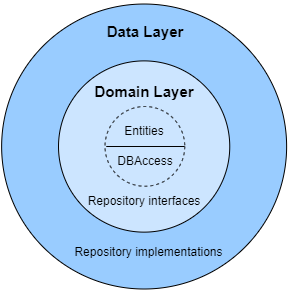
To provide an abstraction of the data access methods, the Repository Pattern is being used. In this layer the implementations of the repository interfaces are found. As well as any other necesary implementation such as the Unit of Work.
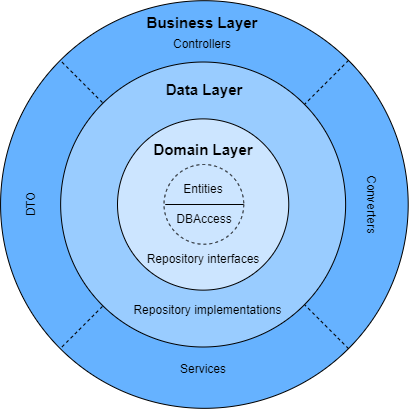
Business Layer
The business layer holds all the application logic and core functionality. It may implement each required API controller as well as the services that go along with them.
Sometimes services or interfaces defined at this layer will need to work with non-entity types. These objects are known as data transfer objects (DTOs) and they are used to decouple the logic from the domain. This enables the data to be optimized and made available to a variety of data users. Thanks to a series of converters, the data can be optimized and be ready for different consumers.
Application Layer
The outer layer of our onion encapsulates the different front-end clients and its resource dependencies. Following also Test-Driven-Development (TDD) principles we will find the Tests.
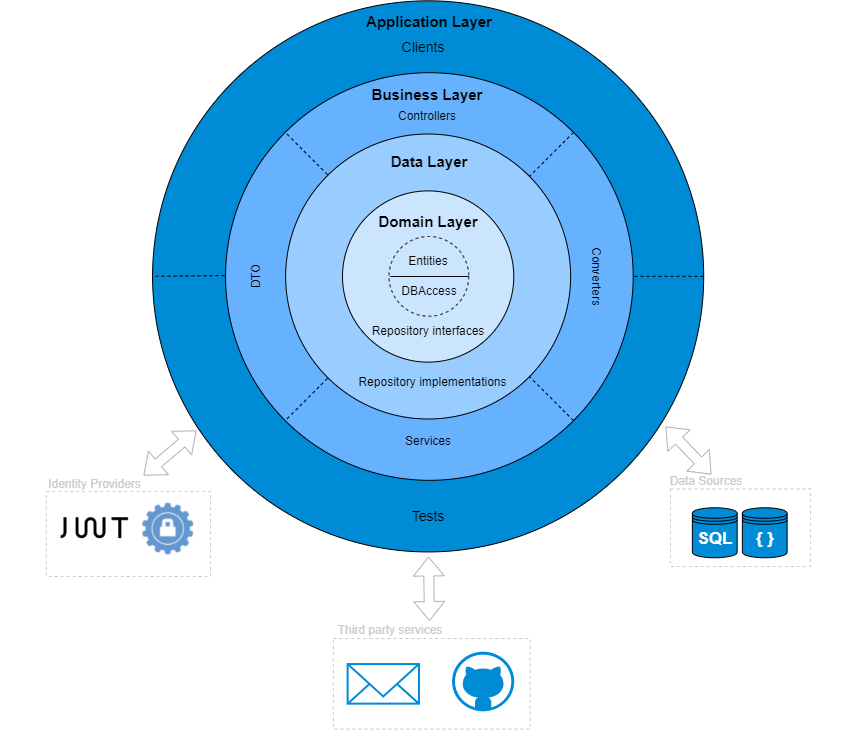
As shown in the diagram, this layer may use many external components such as data sources, identity providers and other services.
References
Here are some interesting references to continue learning about this topic: